Now Reading
AI and Privacy: Everything You Need To Know About Trust and Technology
Below, we get you to the basics of AI and privacy – finding out what it is, what it means in today’s world and what are some of the best practices when it comes to developing a secure and trustworthy AI.
AI and Privacy: Everything You Need To Know About Trust and Technology
Below, we get you to the basics of AI and privacy – finding out what it is, what it means in today’s world and what are some of the best practices when it comes to developing a secure and trustworthy AI.
Published 08-09-22
Submitted by Ericsson

Originally published by Ericsson
By Dario Casella, Head of Ericsson Product Privacy Office, and Laurence Lawson, Privacy Specialist, Ericsson Product Privacy Office
Artificial Intelligence. It has been around in our cultures one form or another since the times of the Ancient Greeks and their myths, through to Frankenstein, and Asimov. This long and storied history cannot take away from the fact that AI is now front and center in our world. AI technology is both for Ericsson and our customers a key business enabler.
Looking back at the history of AI, we see a recurring theme. Implications on privacy and human rights. Using AI wrongly, or without due diligence can lead to a widespread escalation of problems on many fronts.
Today, to mitigate those risks, we are seeing attempts to regulate AI both in industry and government, and build a foundation of trustworthiness that can keep the fictitious stories mentioned above simply that: a work of fiction.
What’s needed to make AI align with humans’ moral and ethical principles? Find out in Ericsson’s AI Ethics Inside report.
The first question: What is AI?
Before we begin to look at the implications of AI on privacy, let’s define what it means.
Of utmost importance here is to first clarify what ’AI’ means, as it can mean different things to different people, and there is no agreed definition in the industry around it. Therefore, we will attempt to describe how we deal with the definition within Ericsson. At Ericsson, we look at AI as a set of technologies (for example machine learning, deep learning) which enable functions, such as image recognition, text generation or text analysis. Such technologies display a certain degree of autonomy and resemble to some extent the ability of a human to ‘reason’ and arrive at a conclusion.
We have the Ericsson Ethics Guideline for Trustworthy AI, which itself has its foundations in the EU’s own guidelines for trustworthy AI. This EU guideline highlights three key elements for AI and how we build trustworthiness.

How does AI work?
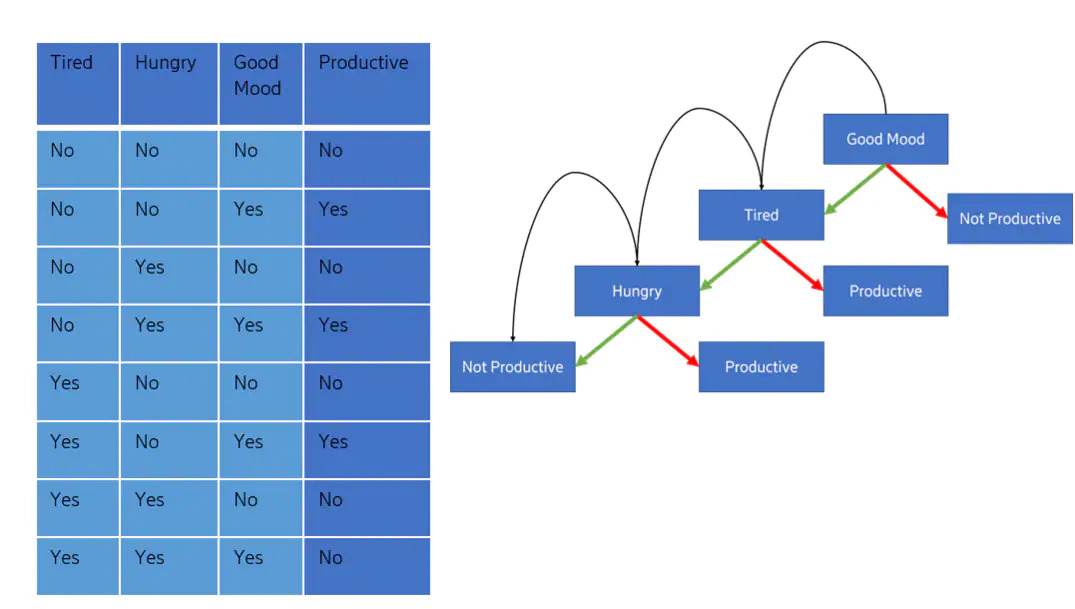
AI is based on models. To explain this, we take as an example a simple decision tree. The process of which starts at the top and then moves down branches at lower levels based on a decision. This technique is often used with smaller sets of data as it offers great transparency, but may pose difficulties to understand with an increasing amount of data.
In essence, what this model demonstrates is the following: “If you are in good mood, and you are tired, and you are hungry, you will not be productive”.
However, this model also illustrates the impact of bias in AI. For example, if we look at how this model works and progresses, it comes up with the scenario wherein the model ’decides’ that a hungry person is not productive. That is an inflection point in the decision: “hungry -> not productive”. “Not hungry -> productive”.
It becomes apparent that bias per se is not good nor bad, fair nor unfair. It is just the inflection point where the model decides ’A’ instead of ’B’. We can all relate to what this model describes, as we have all been hungry and felt how unproductive we are in such a situation. If we go one step further, and apply this to a privacy perspective, we can see how this type of bias would be unfair if instead the AI ’decided’ that a lack of productivity instead was borne out of gender or age.
What is the relationship between AI and privacy?
With increased digitization of consumer-centric applications, media, information and commerce we have witnessed major developments in technology and the usage of artificial intelligence in the past years. We have also seen that not all AI makes use of personal information. In fact there are plenty of use cases in 5G networks aimed at improving infrastructure’s quality and reliability that do not need to feed AI with privacy related data.
On the other hand, when it comes to AI and privacy, we have also noticed that privacy impact must be handled with extra care. For example, AI systems may have the capability to single out and identify an individual who supposedly was not identifiable from the input dataset’s perspective. Such identification may happen even accidentally as a result of the AI computation, exposing the individual in question to unpredictable consequences. For these reasons we explain later in the blog what methodology we have developed and the needed steps to ensure a satisfactory level of privacy in developing AI systems.

How can we trust AI systems?
So, that’s the basics out of the way. Now let’s look at how to construct trustworthy AI (with inherent privacy by design) in a live system. And where better to start than network systems – an area where we see an increasing use of AI and significant changes going forwards.
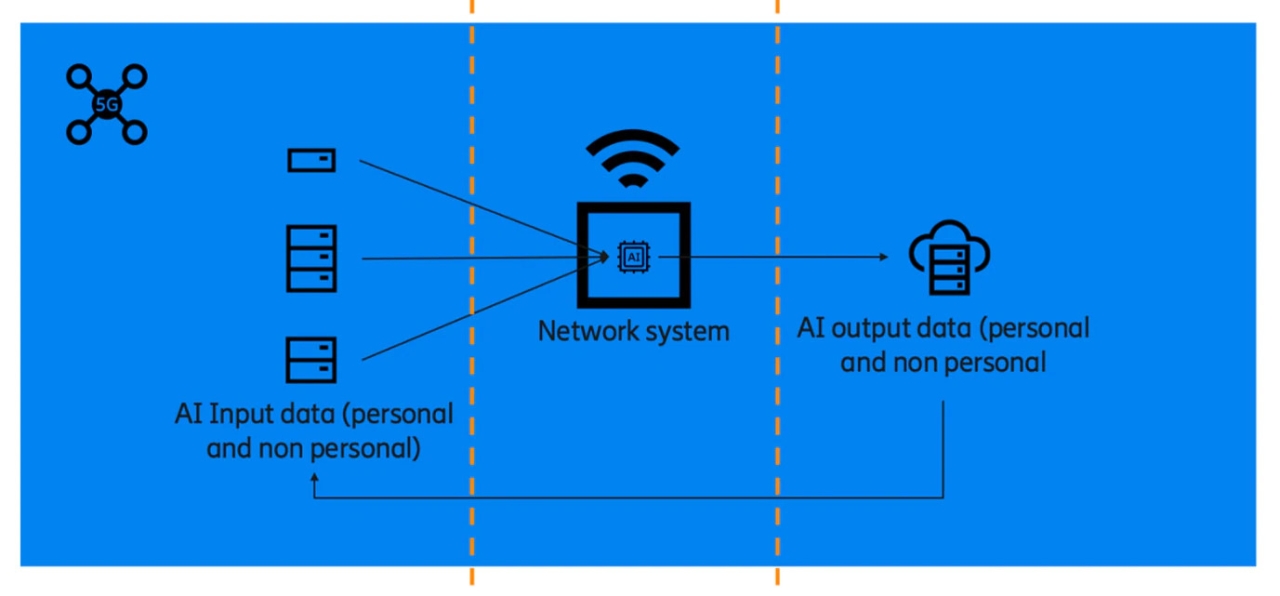
Here, as with all AI systems, there are three key interfaces to work with: the AI input data, the AI actually within the network, and the AI output data. All three areas have key privacy concerns, and, in order to ensure we have trustworthy AI at each step, we work towards having requirements imposed on those within Ericsson who work with AI at each stage. We base these requirements on legal obligations, customer requests, and what we see as best practices and attempts to make these requirements aligned to the direction in which we see industry moving.
Input data
Input data is rather simple to understand. Quite simply, it is the data used to feed the AI model. This can be personal or non-personal by nature. Regardless of how it is defined, we need to ensure rules are in place as it can’t be determined exactly what can be produced at the end (personal data can even be made in the system, or at least inferred). This, coupled with the broad nature of personal data definitions leaves little to no room for error.
At Ericsson, we have requirements in place covering everything from data quality, the ability to de-identify the data, data minimization, and the ability to separate data into production, test, and training data.
The black box stage
The middle of the process, or the black box stage, is perhaps the most difficult area to explain in detail.
This is for two main reasons: Firstly, this is the stage where the machine learning and reasoning models are put into play which can, at times, be difficult to explain. Secondly, given the business importance surrounding these often business-sensitive processes, any attempt to explain (unless where legally obliged) may risk revealing trade secrets.
However, what we can say is that at Ericsson we have strict requirements at this stage which includes aspects such as accountability, transparency, an ability to explain the AI, and configuration protection.
Output data
Finally, we have the output data. It is once again worth mentioning here that, just because we know and control the input data, and we have knowledge of what happens within the ’black box’, there can still be surprises and new data produced in the outcome. This data also has the potential of being sensitive in its nature, which can add to the protection we need to afford it. Rules we have here start in the same vein as the input data in terms of data quality, access control, and general data security. However, we also have additional requirements here such as notifying users about the use of AI, providing the ability to explain the results, and, interestingly, the need to obtain authorization before building a data loop.
Types of data sets used in AI
For many, ’data’ is a broad topic, and, especially within the world of privacy. Even personal data, something often suggested as being narrow by definition, is such a varying and diverse term.
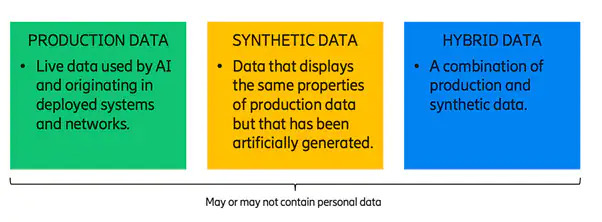
When it comes to AI, the use of data is broadened into ’types of data sets’. There are three distinct types we deal with at Ericsson when it comes to AI: production data, synthetic data and hybrid data.
Production data
Production data is the actual live data which is fed into the AI from a deployed system or network. This is where the requirements kick in and provide strict rules governing the storage, usage, and outcomes; largely due to the fact that these data sets are likely to contain personal information.
Synthetic data
Data that displays the same properties as production data but it does not contain real subscriber data and has been artificially generated. This data can be handled with a much lower risk level from privacy perspective as it does not identify directly or indirectly an individual. This data is commonly used to train, test and verify the outcomes of AI.
Hybrid data
A combination of production data and hybrid data. Such data carries certain privacy implications, like the identifiability of individuals. On the other hand, this data is also extremely useful to simulate real life production scenarios and therefore it can be used to train, test and verify the outcomes of AI.
Naturally skewed data sets vs inherent bias
It’s important to note that all of the aforementioned data sets can be naturally skewed based purely on the sample. For example, a data set which contains more male engineers than female engineers could lead to biased results which harm the minority of the sample featured in the data set from a privacy perspective. This always needs to be considered when assessing privacy impact.
Assessing privacy impact in AI
The most effective way to identify which inherent privacy risks are attached to data sets, and with AI in general, is to perform a Privacy Impact Assessment (PIA). When it comes to Ericsson, our internal PIA is a well-established practice which has been refined over years.
However, due to the fluid nature of AI, we have created an additional way of assessing privacy for those who seek to use AI; this needs to be completed and provides not only the privacy assessor with in-depth knowledge of what the AI implications are, but also gives concrete information about what is going on. We split this into four key sections:
- Assessing AI use cases: The intended use cases should be described, including the input data needed, the data processing operations, and the intended outcome.
- Algorithmic Impact Assessment: The algorithm should be assessed from a privacy perspective and the possible privacy impact of the algorithm should be documented. In Ericsson’s internal guidance, we list several questions here to help steer the course.
- Design Choice and Rationale: It should be explained why certain design choices were made when developing the AI system. The explanation shall cover details around what data is processed and how it is processed in the system.
- Output Verification Level results: It shall be described if and under what conditions the results may not be aligned with the expectations of the use cases, following a risk-based approach.
The future of AI and privacy
Understandably, the topic of AI and privacy is both long and complex. We hope to have summarized some of the key points mentioned above, ranging from the importance of it to how it is evolving today. We have also touched on how Ericsson approaches and ensures that - with all of our AI technologies - privacy is embedded in the process from start to finish.
Ericsson follows the EU’s definition of AI and all its inherent features. This includes the fact that our AI has to be lawful, ethical and robust. We are aware that the futures of privacy and AI are very much intertwined due to their nature; and this is further exemplified by recent cases and their associated fines.
We are aware that the entire landscape of AI is changing. From the technologies being used, the customer needs for smarter AI, and the regulations which are coming thick and fast. Even if all of these AI changes don’t directly impact privacy, we need to be prepared. At Ericsson, we can say with confidence that we are ahead of the curve in this regard, and have an adaptable system which can not only match the ongoing pace of evolution, but ensures that we can be in a position to help shape the entire field of AI to one which respects the key principles of privacy going forward.
Learn more
Mobile networks are part of the critical infrastructure for society, industries, and consumers. Learn how Ericsson is buildibng trustworthy systems to meet those critical requirements.
Read Ericsson’s ‘AI – ethics inside?’
Read the Ericsson white paper: Explainable AI – how humans can trust AI.
Read the Ericsson Tech Review AI special edition 2021
Ericsson
Ericsson
Ericsson is one of the leading providers of Information and Communication Technology (ICT) to service providers. We enable the full value of connectivity by creating game-changing technology and services that are easy to use, adopt, and scale, making our customers successful in a fully connected world.
Our comprehensive portfolio ranges across Networks, Digital Services, Managed Services and Emerging Business; powered by 5G and IoT platforms.
More from Ericsson